帝国cms增加采集节点图文详解步骤
增加采集节点
增加采集节点:也可以说是新增一个采集任务。
说明:每个系统模型都有自己的采集,无论是内置的还是用户自定义的系统模型,新闻系统有新闻系统采集,下载系统有下载系统采集等等。
增加采集基本流程
1、增加采集节点;
2、预览采集正则是否正确;
3、预览无误后即可开始采集。
增加采集节点
1、登录后台,单击“栏目”菜单,选择“增加采集节点”子菜单,进入选择入库栏目界面:
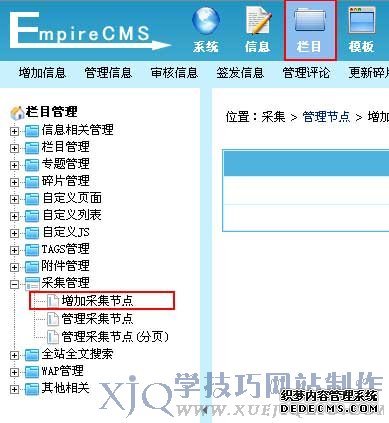
2、进入选择入库栏目界面:(也就是选择采集的信息存放到哪个栏目)
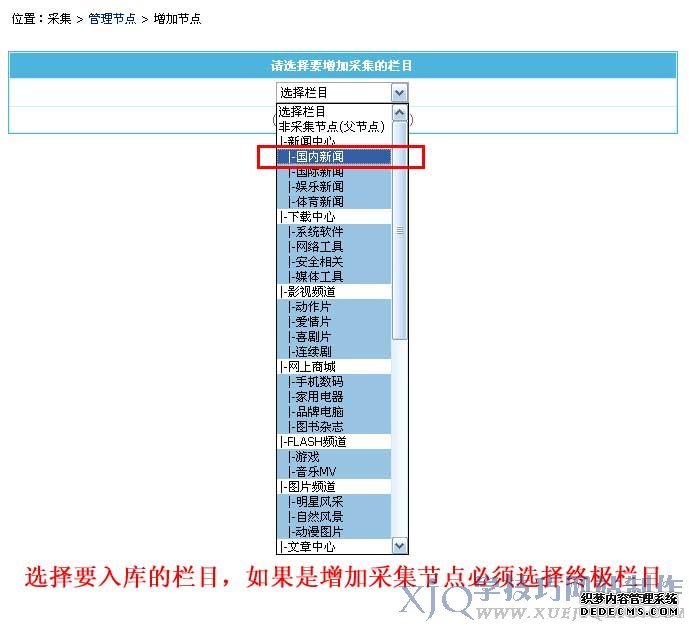
3、选择入库栏目后,进入“增加采集节点”页面,如下图:
| 基本信息 | |
| 节点名称 | 此节点的名称 |
| 父节点 | 可选择上级节点,主要方便管理,比如你可以把所有新闻的采集都归到一个父节点里。 |
| 采集页面地址 | 要采集的页面列表,如果是多个列表用回车格开。 |
| 采集页面为直接内容页:说明填写的地址为直接内容页面地址。 | |
| 采集页面地址方式二 | 由系统自己生成列表,但必须是有数字规律的。 |
| 如:“http://www.phome.net/index.php?page=[page]”([page]则为页码的范围) | |
| 内容页地址前缀 | 信息页链接的地址前缀。如地址前面没域名的话,系统会加上此前缀。 如:http://www.phome.net+/news/2006/1.html |
| 图片/FLASH地址前缀 | 新闻内容的图片/FLASH地址为相对地址时使用。(针对newstext字段,远程保存时有效) |
| 入库栏目 | 采集的数据要入库的栏目。如本节点不是采集节点,请不选。(只列出属于此系统模型的栏目) |
| 入库专题 | 采集的数据要入库的专题。 |
| 节点生效时间 | “开始时间”与“结束时间”这个目前可随意设置。这主要是以后版本扩展之用。 |
| 备注 | 备注或说明 |
| 选项 | |
| 默认相关关键字 | 截取标题前几个字符作为相关链接的“关键字”,推荐设为0,这样入库效率更高。 |
| 采集记录数 | 可设置只采集前多少条记录。("0"为不限,系统会从头采到页面尾) |
| 远程保存图片到本地 | 选择后入库时系统会远程保存图片到本地,还可设置是否加水印。(针对newstext字段) |
| 远程保存FLASH到本地 | 选择后入库时系统会远程保存FLASH到本地。(针对newstext字段) |
| 标题图片设置 | 可设置选择远程保存第几个图片作为标题图片及生成缩图设置。 |
| 每组列表采集个数 | 采集列表页每组记录数,单采集列表页请填1。 |
| 每组信息采集个数 | 采集信息页数据每组记录数 |
| 每组入库数 | 如果要远程保存图片/FLASH则请设小,如设为1。(为防止入库超时,系统推荐将php的超时设为360以上) |
| 每组采集时间间隔 | 针对部分网站限制了页面刷新时间间隔而设置的项 |
| 附加选项 | |
| 页面编码转换 | 页面编码的转换设置。 |
| 是否重复采集同一链接 | 可设置同一链接是否重复采集。 |
| 是否隐藏已导入的信息 | 推荐选隐藏。否则入库后的记录依然会显示到入库列表里。 |
| 采集后自动入库 | 可设置采集后自动入库,不需要人工去入库。但有可能入库超时中断。 |
| 入库后自动删除已导入的信息:入库后同时删除备份的验证记录。 | |
| 整体页面过滤正则 | 格式:“广告开始[!--pad--]广告结束”。多个可用“,”格开。 |
| 针对整个页面代码进行过滤。 | |
| 对整个页面字符替换 | 原字符多个请用","格开,如果是新字符是多个,可以用","格开,系统会一一对应进行替换。 |
| 过滤选项 | |
| 采集关键字 | 标题包含关键字的信息才会采集。如不限制,请留空。多个请用","格开 |
| 替换 | 原字符多个请用","格开,如果是新字符是多个,可以用","格开,系统会一一对应进行替换。 |
| (针对标题与内容) | |
| 过滤广告正则 | 格式:“广告开始[!--ad--]广告结束”,多个请用","格开。(针对newstext字段) |
| 内容为空不采集 | 如果newstext内容为空不采集设置项。 |
| 过滤相似 | 可设置不采集标题相似超过多少个字符的信息。如不限制请填"0"。 |
| 可设置不采集标题完全相同的信息 | |
| 截取内容简介 | 如果信息简介(smalltext)没有值的话,系统会依此设置截取新闻内容(newstext)多少字符作为简介。 |
| 列表页正则 | |
| 信息链接区域正则 | 通常不需要设置。一般是设置只采集页面某一区域的链接或缩小采集范围才设置的 |
| 在要采集链接区域的代码地方加上“[!--smallurl--]” | |
| 信息页链接正则 | 采集“内容页链接”的正则(列表页里) |
| 在信息页链接的地方加上“[!--newsurl--]” | |
| 标题图片正则 | 采集“标题图片地址”的正则,可设置远程保存与地址前缀(列表页里,如图片在内容页,请留空) |
| 在标题图片地址的地方加上“[!--titlepic--]” | |
| 内容页分页采集设置:(如没有分页请留空,针对newstext字段) | |
| 说明:如果是全部列表式,则只需看第一页的页面HTML代码。 | |
| 入库是否保留原分页 | 如果选择“不保留分页”则入库后的信息都不分页。 |
| 分页形式 | 有“上下页导航式”与“全部列出式”两种形式。(一般全部列出式用的比较多) |
| "全部列出"式正则设置 | 分页区域正则([!--smallpageallzz--]) |
| 分页链接正则([!--pageallzz--]) | |
| "上下页导航"式正则设置 | 分页区域正则([!--smallpagezz--]) |
| 分页链接正则([!--pagezz--]) | |
采集相关注意事项
1、按通常设置,同一链接不重复采集。
2、没有标题的信息不采集。
3、非固定内容可用“*”代表任意字符。
4、对于特殊字符请在前面加上“\\”,当然直接将特殊字符改为“*”最合适了。特殊字符如下:
“ )”、“(”、“{”、“}”、“[”、“]”、“\”、“?”等等。
5、正则要找出唯一性的开头字符。有时候空格都会成为识别的依据。
6、增加节点后最好先预览节点,预览无误后才开始采集。(管理采集节点那可预览)

7、"时间正则":为空的话,将为入库时间
-
用微信 “扫一扫”
将文章分享到朋友圈。
关注公众号:xue-jiqiao
本文版权归原作者所有,转载请注明原文来源出处,学技巧网站制作感谢您的支持!
发表评论:
最新建站教程
猜你也喜欢看这些